New algorithm paves the way for light-based computers
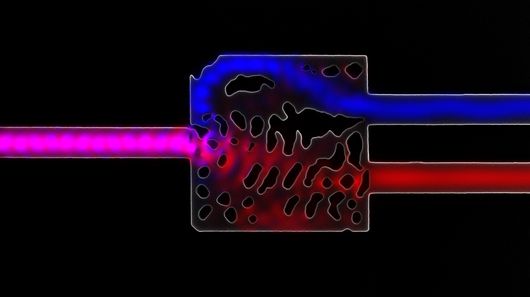
Optical interconnects made of silicon act as a prism to direct infrared light transferring data between computer chips
An inverse design algorithm developed by Stanford engineers enables the design of silicon interconnects capable of transmitting data between computer chips via light. The new process replaces the wire circuitry used to relay information electronically, which could lead to the development of highly efficient, light-based computers.
While the heavy lifting in computer processing takes place inside the chips, an analysis by Stanford professor of electrical engineering, David Miller, showed that up to 80 percent of a microprocessor’s power is eaten up by the transmitting of data as a stream of electrons over wire interconnects. Basically, shipping requires far more energy than production, and chewing through all that power is the reason laptops heat up.
Inspired by the optical technology of the internet, the researchers sought to move data between chips over fiber optic threads beaming photons of light. Besides using far less energy than traditional wire interconnects, chip-scale optic interconnects can carry more than 20 times more data.
The majority of fiber optics are made from silicon, which is transparent to infrared light the same way glass is to visible light. Thus, using optical interconnects made from silicon was an obvious choice. “Silicon works,” said Tom Abate, Stanford Engineering communications director. “The whole industry knows how to work with silicon.”
But optical interconnects need to be designed one at a time, making the switch to the technology impractical for computers since such a system requires thousands of such links. That’s where the inverse design algorithm comes in.
The software provides the engineers with details on how the silicon structures need to be designed for performing tasks specific to their optical circuitry. The group designed a working optical circuit in the lab, copies were made, and all worked flawlessly despite being constructed on less than ideal equipment. The researchers cite this as proof of the commercial viability of their optical circuitry, since typical commercial fabrication plants use highly precise, state-of-the-art manufacturing equipment.
While details of the algorithm’s functions is a tad complex, it basically works by designing silicon structures that are able to bend infrared light in various and useful ways, much like a prism bends visible light into a rainbow. When light is beamed at the silicon link, two wavelengths, or colors, of light split off at right angles in a T shape. Each silicon thread is miniscule – 20 could sit side-by-side within a human hair.
The optical interconnects can be constructed to direct specific frequencies of infrared light to specific locations. And it’s the algorithm that instructs how to create these silicon prisms with just the right amount and bend of infrared light. Once the calculation is made as to the proper shape for each specific task, a tiny barcode pattern is etched onto a slice of silicon.
Building an actual computer that uses the optical interconnects has yet to be realized, but the algorithm is a first big step. Other potential uses for the algorithm include designing compact microscopy systems, ultra-secure quantum communications, and high bandwidth optical communications.
The team describes their work in the journal Nature Photonics.
References:http://www.gizmag.com/