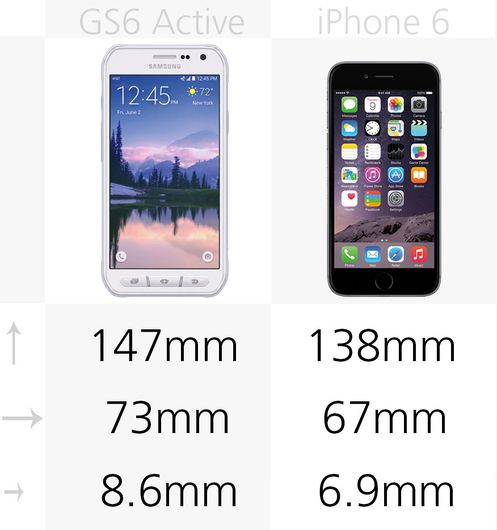
People talk about ‘data being the new oil’, a natural resource that companies need to exploit and refine. But is this really true or are we in the realm of hype? Mohamed Zaki explains that, while many companies are already benefiting from big data, it also presents some tough challenges.
Government agencies have announced major plans to accelerate big data research and, in 2013, according to a Gartner survey, 64% of companies said they were investing – or intending to invest – in big data technology. But Gartner also pointed out that while companies seem to be persuaded of the merits of big data, many are struggling to get value from it. The problem may be that they tend to focus on the technological aspects of data collection rather than thinking about how it can create value.
But big data is already creating value for some very large companies and some very small ones. Established companies in a number of sectors are using big data to improve their current business practices and services and, at the other end of the spectrum, start-ups are using it to create a whole raft of innovative products and business models.
At the Cambridge Service Alliance, in the Department’s Institute for Manufacturing, we work with a number of leading companies from a range of sectors and see first-hand both the opportunities and challenges associated with big data.
Take a company which makes, sells and leases its products and also provides maintenance and repair services for them. Its products contain sensors that collect vast amounts of data, allowing the company to monitor them remotely and diagnose any problems.
If this data is combined with existing operational data, advanced engineering analytics and forward-looking business intelligence, the company can offer a ‘condition-based monitoring service’, able to analyse and predict equipment faults. For the customer, unexpected downtime becomes a thing of the past, repair costs are reduced and the intervals between services increased. Intelligent analytics can even show them how to use the equipment at optimum efficiency. Original equipment manufacturers (OEMs) and dealers see this as a way of growing their parts and repairs business and increasing the sales of spare parts. It also strengthens relationships with existing customers and attracts new ones looking for a service maintenance contract.
In a completely different sector, an education revolution is under way. Big data is underpinning a new way of learning otherwise known as ‘competency-based education’, which is currently being developed in the USA. A group of universities and colleges is using data to personalise the delivery of their courses so that each student progresses at a pace that suits them, whenever and wherever they like.
In the old model, thousands of students arrive on campus at the start of the academic year and, regardless of their individual levels of attainment, work their way through their course until the point of graduation. In the new data-driven model, universities will be able to monitor and measure a student’s performance, see how long it takes them to complete particular assignments and with what degree of success. Their curriculum is tailored to take account of their preferences, their achievements and any difficulties they may have. For the students, this means a much more flexible way of working which suits their needs and gives them the opportunity to graduate more quickly. For the institutions, it means delivering better quality education and hence achieving better student outcomes, and being able to deploy their staff more efficiently and more in line with their skills and interests.
To get value out of big data, however, organisations need to be able to capture, store, analyse, visualise and interpret it. None of which is straightforward.
One of the main barriers seems to be the lack of a ‘data culture’, where data is wholly embedded in organisational thinking and practices. But companies also face a very long list of challenges to do with data management and processing.
Condition-monitoring services, for example, rely on data transmission, often using satellite systems or digital telephone systems: sometimes there simply is no coverage. Most organisations have vast amounts of data stored in different systems in a variety of formats: bringing these together in one place is difficult.
The whole issue of data ownership is problematic in a service contract environment, where the customer considers it to be their data, generated by their usage, while the service provider may consider it to be theirs as it is processed by their system.
In complex data landscapes, security – managing access to the data and creating robust audit trails – can also be a major challenge as, sometimes, is complying with the legislation around data protection. Many organisations also suffer from a lack of techniques such as data and text-mining models, which include statistical modelling, forecasting, predictive modelling and agent-based models (or optimisation simulations).
Where established organisations may find it hard to move away from their entrenched ways of doing things, start-ups have the luxury of being able to invent new business models at will. At the Cambridge Service Alliance we have also been looking at these new ways of doing things in order to understand what business models that rely on data really look like. The results should help companies of all sizes – not just start-ups – understand how big data may be able to transform their businesses. We have identified six distinct types of business model:
Free data collector and aggregator: companies such as Gnip collect data from vast numbers of different, mostly free, sources then filter it, enrich it and supply it to customers in the format they want.
Analytics-as-a-service: these are companies providing analytics, usually on data provided by their customers. Sendify, for example, provides businesses with real-time caller intelligence, so when a call comes in they see a whole lot of additional information relating to the caller, which helps them maximise the sales opportunity.
Data generation and analysis: these could be companies that generate their own data through crowdsourcing, or through smartphones or other sensors. They may also provide analytics. Examples include GoSquared, Mixpanel and Spinnakr, which collect data by using a tracking code on their customers’ websites, analyse the data and provide reports on it using a web interface.
Free data knowledge discovery: the model here is to take freely available data and analyse it. Gild, for example, helps companies recruit developers by automatically evaluating the code they publish and scoring it.
Data-aggregation-as-a-service: these companies aggregate data from multiple internal sources for their customers, then present it back to them through a range of user-friendly, often highly visual interfaces. In the education sector, Always Prepped helps teachers monitor their students’ performance by aggregating data from multiple education programmes and websites.
Multi-source data mash-up and analysis: these companies aggregate data provided by their customers with other external, mostly free data sources, and perform analytics on this data to enrich or benchmark customer data. Welovroi, is a web-based digital marketing, monitoring and analysing tool that enables companies to track a large number of different metrics. It also integrates external data and allows benchmarking of the success of marketing campaigns.
So what does this tell us? That agile and innovative start-ups are creating entirely new business models based on big data and being hugely successful at it. These models can also inspire larger companies (SMEs as much as multinationals) to think about new ways in which they can capture value from their data.
But these more established companies face significant barriers to doing so and may have to deconstruct their current business models if they are to succeed. In the world of fleet and engines this could be by moving to a condition-based monitoring service or, in the education sector, delivering teaching in a completely new way. If companies can’t innovate when the opportunity arises, they may lose competitive advantage and be left struggling to ‘catch up’ with their competitors.
References:http://phys.org/